Form and Function: Machine Unlearning as a Problem of Misaligned States
Abstract
We formulate machine unlearning for online L-BFGS as a counterfactual state-alignment problem. Given an actual event stream and a deletion-edited counterfactual stream, the target of unlearning is the optimizer state that would have arisen had the deleted samples never been processed. We introduce state-aware metrics that separately measure parameter error, memory-operator error, combined state error, and update-direction error. The memory metric compares the inverse-Hessian actions induced by the o-L-BFGS memory, rather than treating curvature pairs as of finite influence. Under convexity assumptions, we derive a recursive bound on counterfactual state deviation. We then evaluate a state-aware benchmark of deletion interventions, including memory-only and parameter-only corrections, against an counterfactual oracle model. These results show that unlearning for online L-BFGS is not merely a parameter-correction problem: it requires alignment with a realizable counterfactual optimizer state.
Cite this work
Show citation formats
Kennon Stewart (2026). Form and Function: Machine Unlearning as a Problem of Misaligned States.@inproceedings{form_and_function_2026,
title={Form and Function: Machine Unlearning as a Problem of Misaligned States},
author={Kennon Stewart},
year={2026},
}Introduction
Machine unlearning is an increasingly popular area of research, but has an evaluation problem. It’s simple enough to conceive of the goal for unlearning a piece of data: the unlearned model should act identically to the model having never seen the data at all. But the function of a model is very different from its form; the description of one without the other is simply incomplete.
This is especially the case for stateful optimizers, which are composed of more than parameters and predictions. Optimizer states exhibit momentum, preconditioned states, and curvature memory that are undescribed by the model’s predictions.
We study this issue in the online L-BFGS optimizer specifically for the task of machine unlearning. The optimizer maintains a finite memory of curvature pairs used to construct an inverse-Hessian approximation. This lasting geometric memory tangibly changes the update direction applied to future gradients. A deletion request therefore raises a structural question. It is not enough to ask whether the current parameter vector performs like the counterfactual parameter vector. We must also ask whether the coupled optimizer state, consisting of parameters and curvature memory, could have arisen from the deletion-edited event stream.
We formulate this as a counterfactual state-alignment problem. Given an actual event history and a deletion-edited counterfactual history, the unlearning target is the optimizer state generated by the counterfactual stream. This reframes unlearning as an ontological question about the state of the learning system. Specifically, can it assume both the form and function of our counterfactual ideal?
Contributions
- We reframe unlearning as a state-alignment task where the optimizer aims to recover the counterfactual state having never learned deleted data.
- We demonstrate the existence of two forms of memory in a second-order optimizer: the curvature information explicitly encoded into the state, and the indirect memory that persists once a curvature point is “forgotten”.
- We introduce unlearning benchmarks that measure state deviation, specifying unlearning for the entire optimizer state.
- We provide theoretical and empirical evidence that parameter-only and memory-only deletion interventions are insufficient for reliable unlearning, while replay-based reconstruction can recover a realizable counterfactual parameter-memory state over a finite horizon.
Related Work
Machine Unlearning
Machine unlearning literature is broadly divided into two methods: exact and approximate [xu_machine_2024].
Exact unlearning removes unlearned data from the model completely. Work by Bourtoule et al. [bourtoule_machine_2020] proposed the SISA method, which partitions the training set into isolated components when training the model. In order to erase data, only a segment of the production model need be pruned, allowing for total erasure of the data. But such methods have been shown to reduce the utility of the model and requires the training set to be kept in-memory. This makes it infeasible for memory-constrained and online environments.
Approximate unlearning brings the unlearned model within a statistical distance of the counterfactual. Suriyakumar and Wilson provide a particularly comprehensive overview [suriyakumar_algorithms_2022]. The literature commonly recommends parameter perturbations to achieve some guaranteed similarity to the counterfactual, with complete retraining being the exact and expensive comparator [sekhari_remember_2021]. Later works allows for compressed representations of curvature memory that reduce time and space complexities [qiao_hessian-free_2025] and even online unlearning with regret guarantees [hu_online_2025] [shen_machine_2025].
Prior work exposed the fallibility of current approximate unlearning methods, notably the presence of residual information in the unlearned model [liu_threats_2025] [chen_when_2021] [stewart_shape_2026]. This demonstrates the insufficiency of unlearning evaluation by comparing performance, and even persists under the more restrictive parameter identify requirement.
There remains an opportunity for an unlearning benchmark specifically for high-dimensional learning. Though black-box metrics (like the predictive performance of the optimizer) is easily evaluated, it doesn’t fully capture the internal dynamics of the unlearned model state, which may differ substantially from that of the counterfactual [jeon_information_2024] [stewart_shape_2026].
Second-Order Optimization
Gradient descent is a family of optimization techniques popular for their interpretability. Numerous works have noted weakness of first-order descent in poorly-conditioned environments, where saddle points and shallow surfaces can slow descent. Second-order optimization improves on prior work by collecting curvature information and accounts for ill-conditioning in the loss surface [cesa-bianchi_prediction_2006].
Newton’s Method is the canonical second-order optimizer, relying explicitly on the Hessian of the loss function to account for conditioning. The combination of gradient and curvature information allows for identical performance on any affine transformation of a loss surface [boyd_convex_2023]. Though the method is useful in particular learning tasks, it’s infeasible in high-rank learning where due to its expensive Hessian inversion operation.
Stochastic and quasi-newton methods emerged as alternatives that addressed such intense calculation. They replace a full Hessian inversion with approximations to varying degrees of compression. The popular BFGS method maintains a Hessian-like preconditioner that is used in place of the Hessian itself [byrd_limited_1995]. This was succeeded by the L-BFGS method, designed specifically for memory-constrained environments, which recursively updates an approximation of the Hessian in its inverse form, negating the need for repeated inversions. More recent work has focused on maintaining these inverse Hessian approximations stochastically, allowing for a method that approaches online learning in its function with a constant memory constraint [qiao_hessian-free_2025].
Problem Setup
Sequential Learning and Unlearning
We define a stream of events, which is produced by some dynamic data-generating process.
Definition (Actual event stream)
Let be the sample space and let be a countable set of sample indices. An event at time is a tuple
where is the event type, is a sample index, and is the sample payload. If , then is inserted into the learner. If , then and the event requests removal of the previously inserted sample with index .
The actual event history up to time is
We distinguish the actual event history seen by the learner with the counterfactual, which excludes the points to have been deleted. The ideal unlearned model would resemble the counterfactual not only in model behavior, but model geometry as well.
Definition (Deletion-edited counterfactual history)
For a deletion set , the deletion-edited counterfactual history is the subsequence
with the original temporal order preserved.
For the realized deletion requests by time , we write
The two event streams produce separate learner states, whose differences indicate the residue of unlearned information.
Definition (Actual and counterfactual learner states)
Let denote the optimizer update map. The actual learner state evolves as
For a deletion set , the counterfactual learner state is the state obtained by applying the same optimizer recursively to the edited history :
In the case of the online L-BFGS optimizer, the optimizer state contains a finite set of curvature pairs used to approximate the curvature of the loss surface. This creates an inherent forgetting mechanism for unlearning data older than the curvature window . So long as the learner is sufficiently insensitive with respect to the deletion candidates, the explicit representation of the unlearned data is erased when the curvature pairs are updated.
Definition (Unlearning operator)
An unlearning operator at time is a map that takes the current optimizer state and a deletion set and returns an unlearned state
Definition (State-alignment error)
Given a metric on learner states, the state-alignment error is
where is the counterfactual optimizer state generated by the deletion-edited history.
The state deviation bound is a new way of measuring the alignment of an unlearned model, but differs from the probabilistic bounds used to define certified machine unlearning. In the case of states that deviate by at most we can write the state deviation bounds with respect to canonical certified unlearning definitions.
Definition (Epsilon-Delta State Certified Unlearning)
Assume that for all deletion sets with
The randomized unlearning operation satisfies -state-certified unlearning if
In application, the state deviation bounds can be substituted for optimizer-specific unlearning certificates. This describes the strength and shape of noise required for injection to certify indistinguishability from the counterfactual ideal. The connection relies on the contractivity assumption for the optimizer descent. Specifically, the calibrated noise injection is determined by the highest possible state deviation between the observed and counterfactual models,
We discuss extensions in the Appendix, including the K-Norm Gradient Mechanism, which provides a noise certificate in the same metric space as the optimizer.
Theoretical Results
Unlearning with an o-LBFGS optimizer
On the other hand, deleted information may persist in the trajectory of later curvature pairs. This stems from the fact that the state of the optimizer at time influences the path and state of later curvature updates . We demonstrate that incoming information, reflecting the counterfactual, will bound and diminish the influence of the perturbation with sufficient time.
Proposition (Direct memory is bounded for finite curvature pairs)
For an o-LBFGS optimizer with memory window , any curvature pair generated at time is no longer stored in the direct memory of for all .
A notable difference between our method and that of prior work is the metric used to diagnose the model’s misalignment with the counterfactual. Prior work emphasizes regret and empirical risk as indicators for model recovery [qiao_hessian-free_2025] [sekhari_remember_2021]. We note that these methods don’t encompass the entire model state, where residual information may persist [chen_when_2021] [bertran_reconstruction_2024] [cooper_machine_2025] [stewart_shape_2026].
For the sake of brevity, we relegate the standard convexity and smoothness assumptions to Appendix: Convexity Assumptions We largely follow those outlined in standard stochastic optimization and unlearning literature [qiao_hessian-free_2025] [byrd_limited_1995]. We restrict our attention to convex optimization, but explore nonconvex optimizers in future work.
Lemma (One-step state-error recursion)
Suppose the optimizer update map is -contractive in and the deletion-induced perturbation at time is bounded by . Then
Which justifies the state deviation bounds for the recursive optimizer state, relying on a discrete Gronwall inequality [liao_discrete_2018].
Theorem (Bounded counterfactual state deviation for finite-memory o-LBFGS)
Under strong convexity, smoothness, bounded gradients, bounded curvature pairs, and contractive o-L-BFGS updates, the state-alignment error satisfies
The optimizer stores only memory.
The theorem above decomposes the counterfactual error into two parts: the initial disruption caused by deletion and the residual memory in the optimizer state. As mentioned, the error persists in the counterfactual model for a period of time bounded by the number of curvature pairs. The sum represents the information stored in the indirect memory, the effects of which decay geometrically with the strength of the map’s contraction.
Defining Certificates on the Optimizer State
Since we have bounds on the state deviation of the optimizer state, we can then define the conditions under which unlearning is certified not only for the parameter, but for the entire optimizer state,
To do this, we step back from unlearning as a deterministic operation. We randomize the event stream over which our model learns (and unlearns) before injecting a noise to the parameter state that is calibrated to the one-step recursion error defined in Theorem 2 (o-LBFGS Unlearning Certificate).
Theorem (o-LBFGS Unlearning Certificate)
The randomized state where is certifiably unlearned if
where Exact unlearning is only obtained when
Theorem 2 (o-LBFGS Unlearning Certificate) describes the noise injection needed to ensure certified unlearning. This surpasses prior parameter-only noise injections by tuning the noise to the optimizer’s set of curvature pairs. We suspect that similar certificates are obtainable for other optimization methods with bounded state deviations.
The primary outcome is future state-error area under the curve,
which measures cumulative deviation from the counterfactual trajectory. The experiment code also reports initial state error, final state error, future parameter-trajectory error, update-direction-error AUC, direct memory mass, average future loss, and intervention cost measured by replayed events, additional gradient evaluations, and wall-clock time.
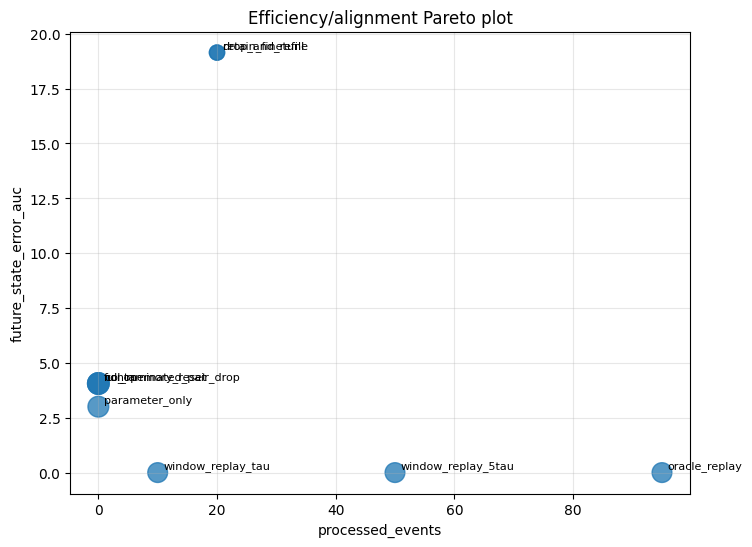
Deletion-mode mechanism evidence. Recent deletions test explicit contamination of the o-LBFGS curvature memory, while random and high-gradient deletions often have zero direct memory mass and therefore test indirect trajectory dependence. The replay methods exactly recover recent deletions because the relevant counterfactual history lies inside the replay window. For random and high-gradient deletions, direct memory mass is typically zero, yet non-replay methods still exhibit large future state-error AUC, indicating that deleted data can persist through the induced parameter trajectory and subsequently generated curvature pairs.
| Deletion / Method | Direct memory mass | Initial state error | Future state AUC | AUC ratio vs. no-op |
|---|---|---|---|---|
| Recent — No-op | 5.000 | 330.537 | 444010.507 | 1.000 |
| Recent — Parameter-only | 5.000 | 122.800 | 436623.291 | 0.876 |
| Recent — Pair drop | 0.000 | 316.275 | 448272.217 | 0.940 |
| Recent — Replay τ | 0.000 | 0.000 | 0.000 | 0.000 |
| Recent — Replay 5τ | 0.000 | 0.000 | 0.000 | 0.000 |
| Random — No-op | 0.000 | 187.849 | 449573.044 | 1.000 |
| Random — Parameter-only | 0.000 | 322.062 | 453589.582 | 1.016 |
| Random — Replay 5τ | 0.000 | 0.007 | 0.891 | 0.694 |
| High-gradient — Replay 5τ | 0.000 | 0.009 | 1.055 | 0.996 |
Stream-type stress test on quadratic and ridge-logistic regimes. Local state edits do not reliably reconstruct the counterfactual optimizer; replay-based methods empirically reduce future state error in both settings.
| Stream / Method | Future state AUC | AUC ratio vs. no-op | Exact recovery rate | Final state error |
|---|---|---|---|---|
| Quadratic — No-op | 1.137 | 1.000 | 0.000 | 4e-6 |
| Quadratic — Parameter-only | 1.062 | 0.871 | 0.000 | 3e-6 |
| Quadratic — Replay 5τ | 0.000 | 0.000 | 0.556 | 0.000 |
| Ridge logistic — No-op | 1012737.545 | 1.000 | 0.000 | 1113.715 |
| Ridge logistic — Replay 5τ | 0.000 | 0.000 | 0.556 | 0.000 |
Experimental Results
We evaluate whether data deletion in online L-BFGS can be treated as a parameter-correction problem, or whether successful unlearning requires recovery of the full optimizer state. The experiments show that deletion influence is not localized to the parameter vector. Instead, deleted data affects the coupled state
where is the parameter vector and is the finite memory of L-BFGS curvature pairs. This coupling matters because future updates depend on both terms. This is important because prior updates impact the path of the optimizer in state space. An intervention that corrects only , or only , generally produces a state that may be closer to the counterfactual along one coordinate, but is not itself a state that would have come from the counterfactual stream of events.
We identify three clear patterns across the experiments. First, parameter alignment understates the persistence of deleted information. Second, curvature memory creates a deletion horizon: even after directly contaminated curvature pairs leave the finite memory window, their influence may persist indirectly through later parameters, later curvature pairs, and future update directions. Third, exact recovery is possible only when the intervention reconstructs the joint parameter-memory state, either by oracle replay or by replay over a window that contains the deletion-relevant optimizer history.
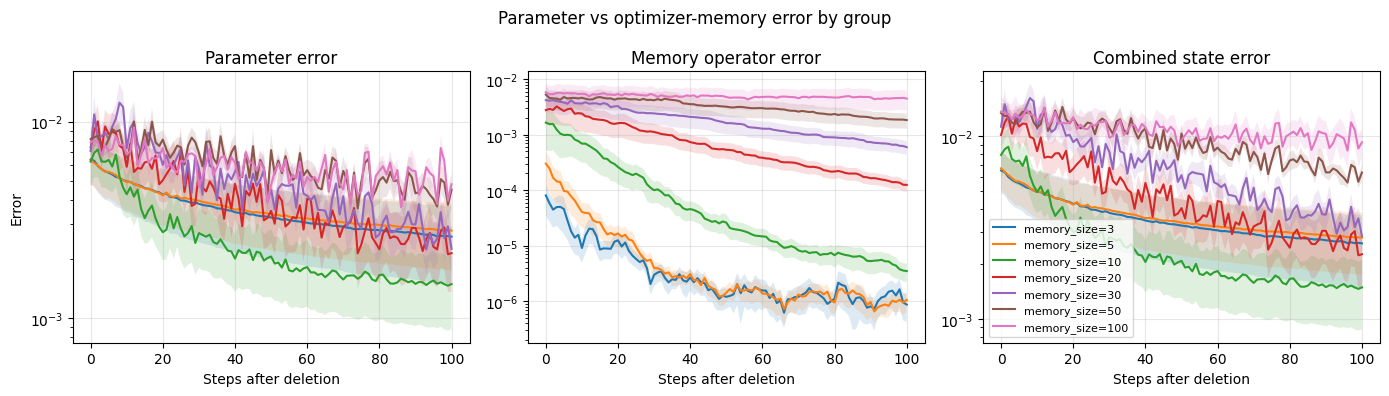
Parameter alignment understates the persistence of deleted information
We begin by comparing parameter error and memory-operator error after deletion. If unlearning were purely a parameter-level problem, then interventions that bring close to the counterfactual parameter would also induce future behavior close to the counterfactual trajectory. The results reject this interpretation, as shown in the error-breakdown figure above. Methods that intervene on only one component of the optimizer state can reduce one discrepancy while leaving the other unresolved.
This is most visible in the comparison between parameter-only correction, memory-only correction, and replay-based methods. The oracle replay baseline produces zero initial state error, zero final state error, and zero future trajectory error because it reconstructs the deletion-edited counterfactual directly. By contrast, the parameter-only intervention applies a correction to while leaving unchanged. This creates a parameter-memory pair that is internally inconsistent: the parameter has been moved as if the deleted data were absent, but the curvature memory still encodes update information from the original trajectory. This produces the largest future trajectory error among the non-oracle methods, with future state-error AUC approximately , compared with for no-op deletion.
This result clarifies why parameter-space deletion is not enough for online L-BFGS. The update direction is computed from both the current gradient and the inverse-Hessian approximation induced by the memory state. If the parameter vector is corrected but the curvature state is not, the next update is not the update that the counterfactual optimizer would have taken. The intervention may therefore remove a first-order trace of the deleted data while preserving a second-order trace in the optimizer memory.
Memory-only interventions have the complementary failure mode. Removing or resetting curvature information can reduce direct contamination, but it does not generally reconstruct the parameter trajectory that would have generated the counterfactual memory. In the aggregate results, full memory reset improves future state-error AUC relative to no-op deletion, but it still remains far from oracle recovery. Its final state error is approximately , with nonzero future trajectory error and large update-direction error. Thus, memory reset can be beneficial as a damage-reduction operation, but it should not be interpreted as exact unlearning. It produces a state with clean or partially cleaned curvature memory attached to a parameter vector that still reflects the deleted trajectory.
The central lesson is that deleted information is not stored in one place. It is distributed across the coupled optimizer state. Successful unlearning therefore requires more than removing contaminated curvature pairs or perturbing parameters. It requires reconstructing a coherent state that could have been produced by the deletion-edited event stream.
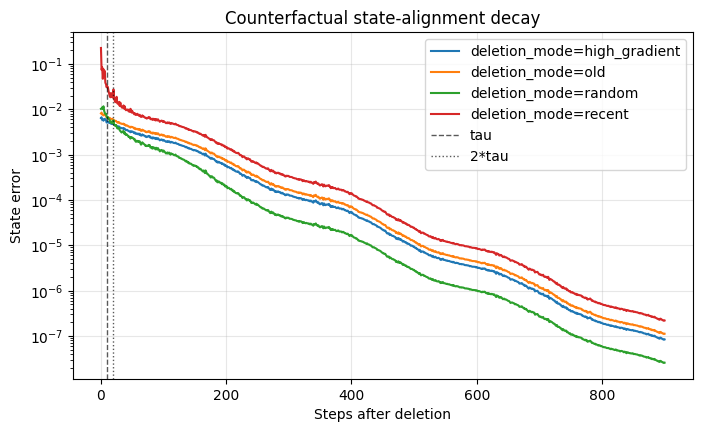
Finite curvature memory creates a pseudo-deletion horizon
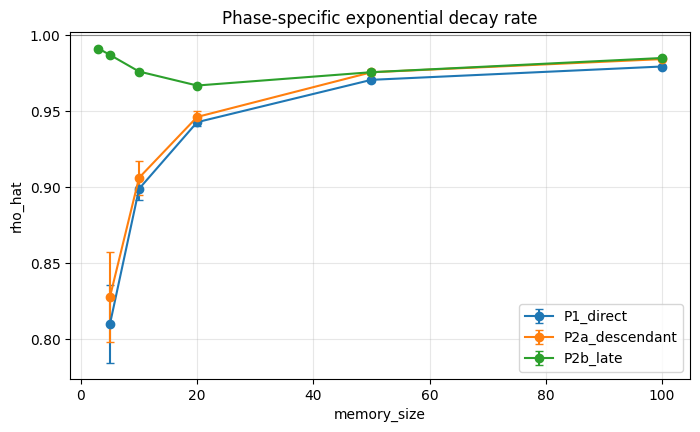
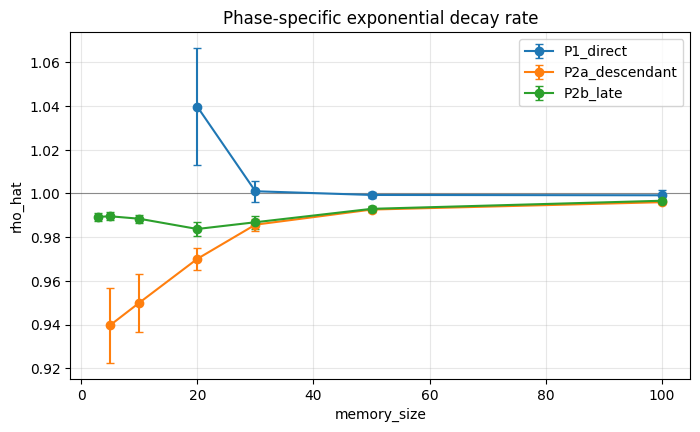
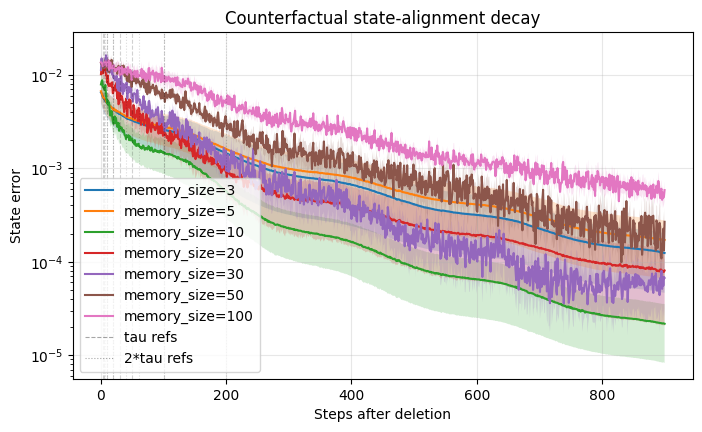
The finite-memory decay experiment isolates how long deletion influence persists after the deletion event. Online L-BFGS stores only a finite number of curvature pairs, so directly contaminated curvature pairs eventually leave memory. This might suggest that deletion becomes automatic after additional updates. The results demonstrate otherwise.
Direct memory does clear after the contaminated curvature pairs rotate out of the L-BFGS window. However, state error does not necessarily vanish at that moment. The deleted data may already have changed the parameter trajectory, and that changed trajectory generates later gradients, later curvature pairs, and later inverse-Hessian actions.
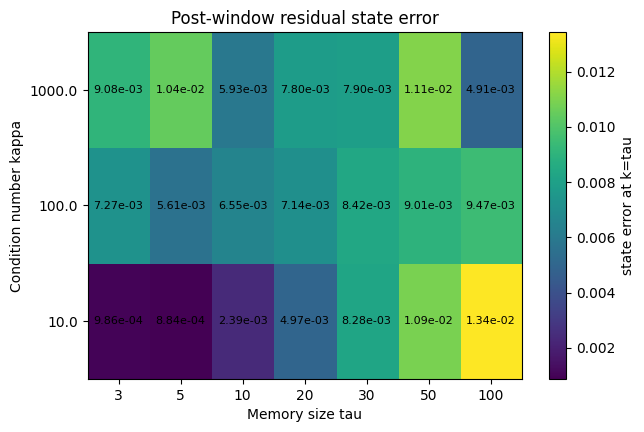
This distinction explains the observed relationship between memory size and recovery. Larger curvature windows retain direct contamination for more steps, but they also slow the model’s alignment. In the memory-depth experiment, parameter error and memory-operator error decay at different rates. Parameter error may decline smoothly, while memory-operator error is more sensitive to the number of stored curvature pairs. This indicates that the memory window controls the length of the optimizer’s historical dependence.
The learning-unlearning cycle requires strategic amounts of forgetting. A larger memory window may improve optimization by retaining more curvature information, but it also increases the burden on the unlearning mechanism. A smaller memory window shortens the deletion horizon, but may weaken the optimizer’s ability to fully utilize second-order structure.
Local deletions reduce some errors but do not reconstruct the counterfactual
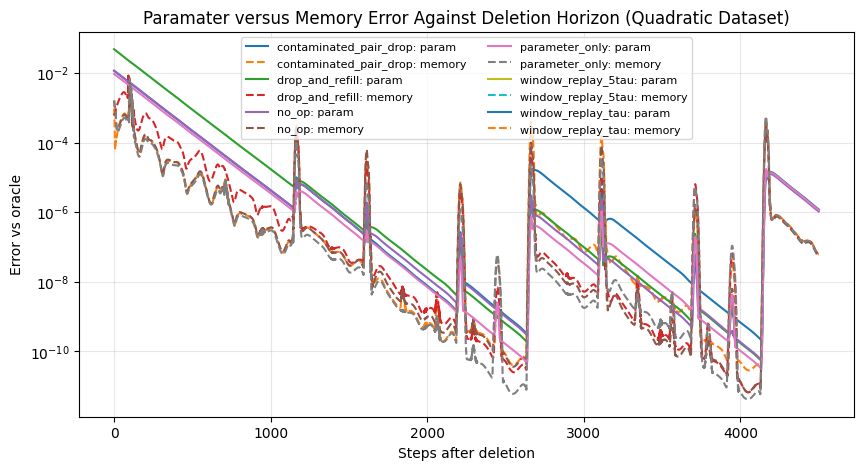
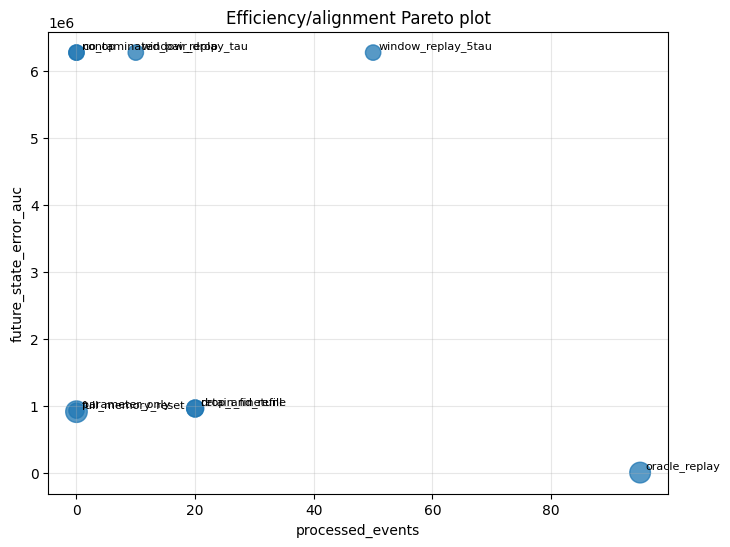
The state-aware benchmark compares deletion-time interventions that modify parameters, memory, both, or neither. The aggregate results show a clear hierarchy. Oracle replay recovers the counterfactual perfectly. Among non-oracle methods, window replay over a larger window gives the lowest future state-error AUC, followed by full memory reset, retain fine-tuning, shorter window replay, contaminated-pair drop, and no-op deletion. The worst methods are drop-and-refill and parameter-only correction.
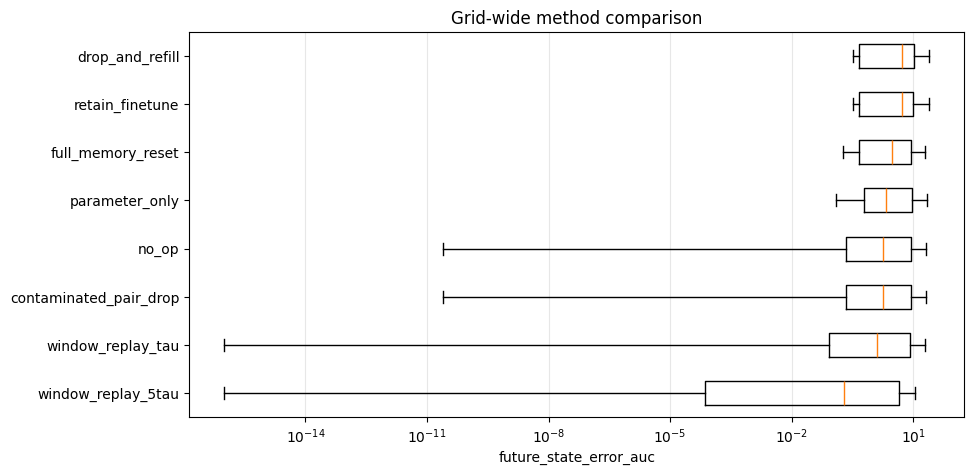
The poor behavior of parameter-only correction is especially important. It is the intervention most closely aligned with standard approximate unlearning literature that evaluates unlearning with parameter distance. But in a stateful optimizer, this correction leaves the curvature memory unexamined. The resulting pair is neither the original state nor the counterfactual; it is a hybrid state that is misaligned with itself. The empirical consequence is large future trajectory error and large future state-error AUC.
Drop-and-refill fails for a related reason. It discards both parameter and curvature information and then allows the optimizer to continue from the remaining stream. This removes contaminated information aggressively, but it also destroys useful information shared by the actual and counterfactual histories. Since the retain data substantially overlaps between the two histories, indiscriminate erasure can move the optimizer farther from the counterfactual than doing nothing. In the aggregate results, drop-and-refill has future state-error AUC approximately , substantially worse than no-op deletion.
Full memory reset and contaminated-pair drop perform better than no-op in the aggregate results, but their interpretation is different from replay. They reduce some memory-based error, especially when deleted data is still directly represented in the curvature window, but they do not reconstruct the counterfactual optimizer state. Their update-direction errors remain large, indicating that the induced future optimization behavior still differs from the counterfactual. These methods are therefore best understood as partial mitigation strategies. They can reduce residual contamination, but they do not solve the misaligned state.
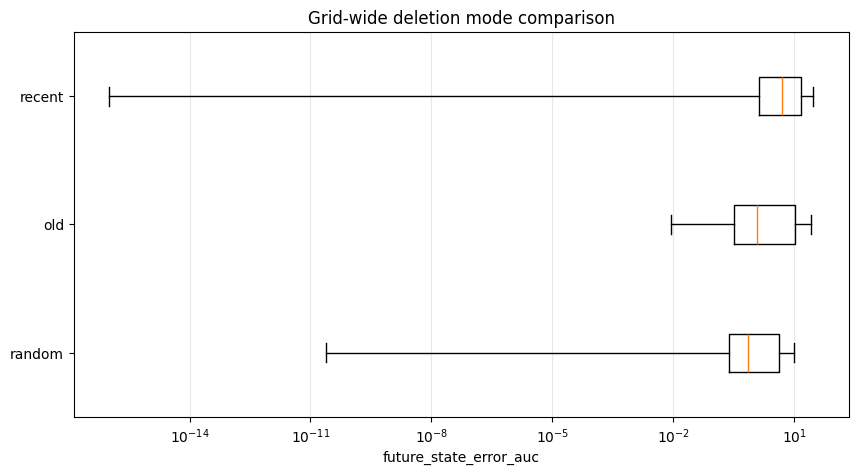
Replay succeeds when strategically timed
Replay-based methods work differently than other interventions because they do not adjust only a single model state. They regenerate the dual parameter-memory state from data that is consistent with the deletion request. This explains why window replay can approach exact recovery under specific conditions (for example, when the deleted data is a subset of the replay window). But the efficiency of replay methods reduces when deleted data passes from direct to indirect memory.
Window replay is a more realistic approximation of an oracle retrained model. Instead of replaying the entire stream, it maintains a recent window of observations and reconstructs the optimizer state from that window after deletion. In the aggregate benchmark, the larger window replay method has the best non-oracle future state-error AUC, approximately , and improves over both no-op deletion and the shorter replay window. It had the lowest future state AUC out of any non-oracle method in 40 of the 108 configuration experiments run.
Discussion
The experiments suggest that unlearning in stateful optimizers should be evaluated as a state reconstruction problem. Parameter-only correction can move toward , and memory-only correction can remove visibly contaminated curvature pairs from , but neither operation guarantees that the resulting pair lies on the counterfactual trajectory. This distinction matters because future o-LBFGS updates are generated by the interaction between the current gradient and the inverse-Hessian approximation induced by memory. A state that is only locally improved will induce an optimizer whose memory is inconsistent with its own parameters, inducing instability in parameter space.
The finite-memory structure of o-LBFGS creates a natural direct deletion horizon: curvature pairs generated from deleted samples eventually leave the memory window. This should not be confused with full unlearning. Direct clearance removes explicit references to deleted data, but the deleted samples may already have changed the parameter trajectory. Later curvature pairs are then generated from parameters that differ from the counterfactual parameters, preserving an indirect residue even after direct memory mass is zero.
The state-alignment view also clarifies what a certificate for stateful unlearning would need to control. Existing certified unlearning mechanisms typically calibrate noise to a sensitivity bound over parameters or empirical-risk minimizers. For o-LBFGS, the relevant sensitivity includes both the parameter and the memory-induced update operator. A state certificate should therefore bound deviations in a metric that captures future optimization behavior, not merely parameter distance.
Limitations and Future Work
This study is limited in four ways. First, the theoretical bounds rely on convexity, smoothness, bounded gradients, bounded inverse-Hessian approximations, and a contractive update assumption. These assumptions isolate the state-alignment mechanism but do not cover general nonconvex training. Second, the experiments use synthetic quadratic and ridge-logistic streams, which allow controlled counterfactual replay but do not yet demonstrate performance on large-scale deployed models. Third, the replay interventions assume access to sufficient event history. This may be infeasible in the case of potentially unbounded data streams and memory-constrained environments like IoT devices.
Appendix: Convexity Assumptions
Definition (Strong convexity and smoothness)
Each loss is -strongly convex and -smooth.
Definition (Bounded stochastic gradients)
There exists such that
for all relevant .
Definition (Bounded inverse-Hessian approximations)
The o-LBFGS inverse curvature matrices satisfy
for constants .
Definition (Contractive update map)
The optimizer update map satisfies
for some .
References
- Xu, Heng, Zhu, Tianqing, Zhang, Lefeng, Zhou, Wanlei, Yu, Philip S. (2024). Machine {Unlearning}: {A} {Survey}. ACM Computing Surveys. https://doi.org/10.1145/3603620
- Bourtoule, Lucas, Chandrasekaran, Varun, Choquette-Choo, Christopher A., Jia, Hengrui, Travers, Adelin, Zhang, Baiwu, Lie, David, Papernot, Nicolas (2020). Machine {Unlearning}. arXiv. https://doi.org/10.48550/arXiv.1912.03817
- Suriyakumar, Vinith M., Wilson, Ashia C. (2022). Algorithms that {Approximate} {Data} {Removal}: {New} {Results} and {Limitations}. arXiv. https://doi.org/10.48550/arXiv.2209.12269
- Sekhari, Ayush, Acharya, Jayadev, Kamath, Gautam, Suresh, Ananda Theertha (2021). Remember {What} {You} {Want} to {Forget}: {Algorithms} for {Machine} {Unlearning}. arXiv. https://doi.org/10.48550/arXiv.2103.03279
- Qiao, Xinbao, Zhang, Meng, Tang, Ming, Wei, Ermin (2025). Hessian-{Free} {Online} {Certified} {Unlearning}. arXiv. https://doi.org/10.48550/arXiv.2404.01712
- Hu, Yaxi, Sch{\"o}lkopf, Bernhard, Sanyal, Amartya (2025). Online Learning and Unlearning. https://doi.org/10.48550/arXiv.2505.08557
- Shen, Shaofei, others (2025). Machine Unlearning for Streaming Forgetting. https://doi.org/10.48550/arXiv.2507.15280
- Liu, Ziyao, Ye, Huanyi, Chen, Chen, Zheng, Yongsen, Lam, Kwok-Yan (2025). Threats, {Attacks}, and {Defenses} in {Machine} {Unlearning}: {A} {Survey}. IEEE Open Journal of the Computer Society. https://doi.org/10.1109/OJCS.2025.3543483
- Chen, Min, Zhang, Zhikun, Wang, Tianhao, Backes, Michael, Humbert, Mathias, Zhang, Yang (2021). When {Machine} {Unlearning} {Jeopardizes} {Privacy}. arXiv. https://doi.org/10.48550/arXiv.2005.02205
- Stewart, Kennon (2026). Shape of {Memory}: a {Geometric} {Analysis} of {Machine} {Unlearning} in {Second}-{Order} {Optimizers}. arXiv. https://doi.org/10.48550/arXiv.2604.23046
- Jeon, Dongjae, Jeung, Wonje, Kim, Taeheon, No, Albert, Choi, Jonghyun (2024). An {Information} {Theoretic} {Evaluation} {Metric} {For} {Strong} {Unlearning}. arXiv. https://doi.org/10.48550/ARXIV.2405.17878
- Cesa-Bianchi, Nicolò, Lugosi, Gábor (2006). Prediction, learning, and games. Cambridge University Press.
- Boyd, Stephen P., Vandenberghe, Lieven (2023). Convex optimization. Cambridge University Press.
- Byrd, Richard H., Lu, Peihuang, Nocedal, Jorge, Zhu, Ciyou (1995). A {Limited} {Memory} {Algorithm} for {Bound} {Constrained} {Optimization}. SIAM Journal on Scientific Computing. https://doi.org/10.1137/0916069
- Bertran, Martin, Tang, Shuai, Kearns, Michael, Morgenstern, Jamie, Roth, Aaron, Wu, Zhiwei Steven (2024). Reconstruction {Attacks} on {Machine} {Unlearning}: {Simple} {Models} are {Vulnerable}. arXiv. https://doi.org/10.48550/arXiv.2405.20272
- Cooper, A. Feder, Choquette-Choo, Christopher A., Bogen, Miranda, Klyman, Kevin, Jagielski, Matthew, Filippova, Katja, Liu, Ken, Chouldechova, Alexandra, Hayes, Jamie, Huang, Yangsibo, Triantafillou, Eleni, Kairouz, Peter, Mitchell, Nicole Elyse, Mireshghallah, Niloofar, Jacobs, Abigail Z., Grimmelmann, James, Shmatikov, Vitaly, Sa, Christopher De, Shumailov, Ilia, Terzis, Andreas, Barocas, Solon, Vaughan, Jennifer Wortman, boyd, danah, Choi, Yejin, Koyejo, Sanmi, Delgado, Fernando, Liang, Percy, Ho, Daniel E., Samuelson, Pamela, Brundage, Miles, Bau, David, Neel, Seth, Wallach, Hanna, Cyphert, Amy B., Lemley, Mark A., Papernot, Nicolas, Lee, Katherine (2025). Machine {Unlearning} {Doesn}'t {Do} {What} {You} {Think}: {Lessons} for {Generative} {AI} {Policy} and {Research}. arXiv. https://doi.org/10.48550/arXiv.2412.06966
- Liao, Hong-lin, McLean, William, Zhang, Jiwei (2018). A discrete {Grönwall} inequality with application to numerical schemes for subdiffusion problems. arXiv. https://doi.org/10.48550/arXiv.1803.09879