The Mathematics Behind Privacy and Machine Unlearning.
Cite this work
Show citation formats
Kennon Stewart (2026). The Mathematics Behind Privacy and Machine Unlearning..@inproceedings{machine_unlearning_2026,
title={The Mathematics Behind Privacy and Machine Unlearning.},
author={Kennon Stewart},
year={2026},
}Easy Learn, Easy Go.
There’s been a lot of focus on models that can learn anything. Early ML researchers (and some holdouts) used to throw every type of data at a model in the hopes that the agent would find something useful [Qiao_Zhang_Tang_Wei_2025].
This is fine for massive weather models or economic forecasts, but it doesn’t work for production machine learning. Most notably because production models work with sensitive people data.
Courts have been catching on to this. The EU passed the largest and most comprehensive data protection law (aptly named the General Data Protection Regulations, GDPR) over a large portion of digital subscribers. California isn’t far behind. Models not only need to be careful with sensitive data, but unlearn it on command.
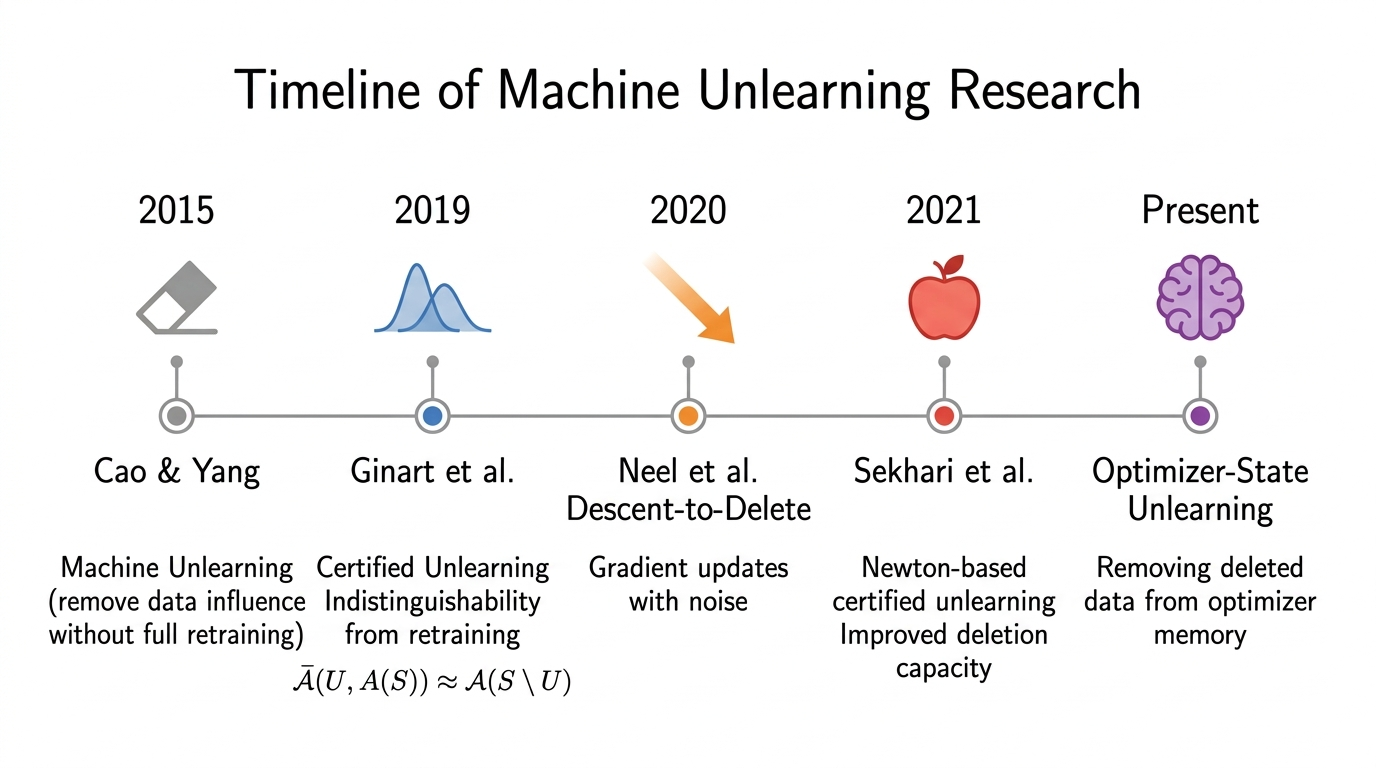
This was the state of things when Cao et al. published their paper coining the term “machine unlearning” [Cao_2015]. They demonstrate that learning is easy for a highly-specialized ML algorithm, but this isn’t the case for removing a user’s influence.
Data Deletion as a Complex Operation.
Deleting data sounds simple in a world where SQL queries have a DELETE command. But some pretty unexpected problems come up when doing so at-scale. Most notably, deleting someone’s data actually leaks their information.
Chen et al. show that adversaries can easily derive the influence of an unlearned datapoint by comparing the model before and after deletion [chen2021].
There’s also the less compelling implementation barriers. Pulling a model for every data deletion request is deeply infeasible, and consumes large amounts of energy. The field was facing a bind: we needed algorithms that could unlearn without pulling the model from production.
The field has come up with a few potential solutions. We can divide them into 3 categories: proactive unlearning, structural unlearning, and algorithmic unlearning.
Based on the results of our latest experiment, we even define a fourth unlearning method for stateful optimizers, more generally.
Proactive Unlearning removes the User’s data before it’s even read.
This sounds simple, and slightly counterintuitive, but that demonstrates the innovation of Cynthia Dwork and Aaron Roth [Dwork_Roth_2014].
A preventative measure is applied to any training set for a model. The data is injected with noise as soon as it’s queried, and the training set is just indistinguishable enough from the original to remove the trace of an individual. And so a company could store a person’s data, use it for simulating new (marginally unrecognizable) data, and still protect their users without touching their production models.
The only issue is that this noise adds up. Anonymizing a single user’s data means spreading their influence to every other observation in the sample. The information is technically still there, but can no longer be attributed to an individual datum. But when this is done for every data point, then the model performance dips. The model is no longer able to correctly estimate a datum’s influence when predicting new cases.
This is especially troubling if a user requests exact unlearning, and we have to remove every trace of the contagious information. The training resembles less and less the true population until all meaningful signal is masked. Sekhari actually proves a fundamental limit on how well a model can learn without actually seeing real data.
It also happens that approximate differential privacy is a bit of a gamble. There is a nonzero probability that the randomized dataset is identical to the original dataset. In this case, the entire dataset is exposed.
Structural Unlearning deletes data by changing the structure of the model itself.
Bourtole et al. had a different approach for exact unlearning [Bourtoule_Chandrasekaran]. Their SISA model almost unlearns data perfectly by partitioning the training set into nonoverlapping sets and training different model segments on different training sets.
The intuition is strong. If User A’s data is only used to train one branch of a decision tree, then that data is easily unlearned by removing that segment of the model. No other part of the model was trained on the data, and so the only cost is that required to retrain the branch.
But this structural unlearning comes at a cost. First, we have to keep track of every single observation used for training. User A’s data deletion request can only be fulfilled if I know which branch of the model had seen the data. In other words, we have to maintain perfect structural knowledge of the model. For online learning, this is something like keeping a potentially unbounded training set in-memory.
There’s also a more fundamental problem: the data is only seen by one part of the model. Its performance is bounded by default because the model undergoes less training, and so such methods are limited in use.
Algorithmic Unlearning brings the untrained model close to the retrained ideal.
Algorithmic methods define the success of unlearning by the model’s similarity to some ideal untrained model. They remove previously restrictive constraints on the structure of a model with the expectation that the influence of the deleted points can be estimated at deletion time.
Ginart et al. proposed this definition because they recognized the costs of proactive and structural unlearning methods, which pay for their privacy [ginart2019]. They instead define the conditions by which a model is declared certifiably unlearned. They carefully measure the difference of the model in in terms of output: the best unlearning algorithm produces a model that does just as well as the ideal unlearned model.
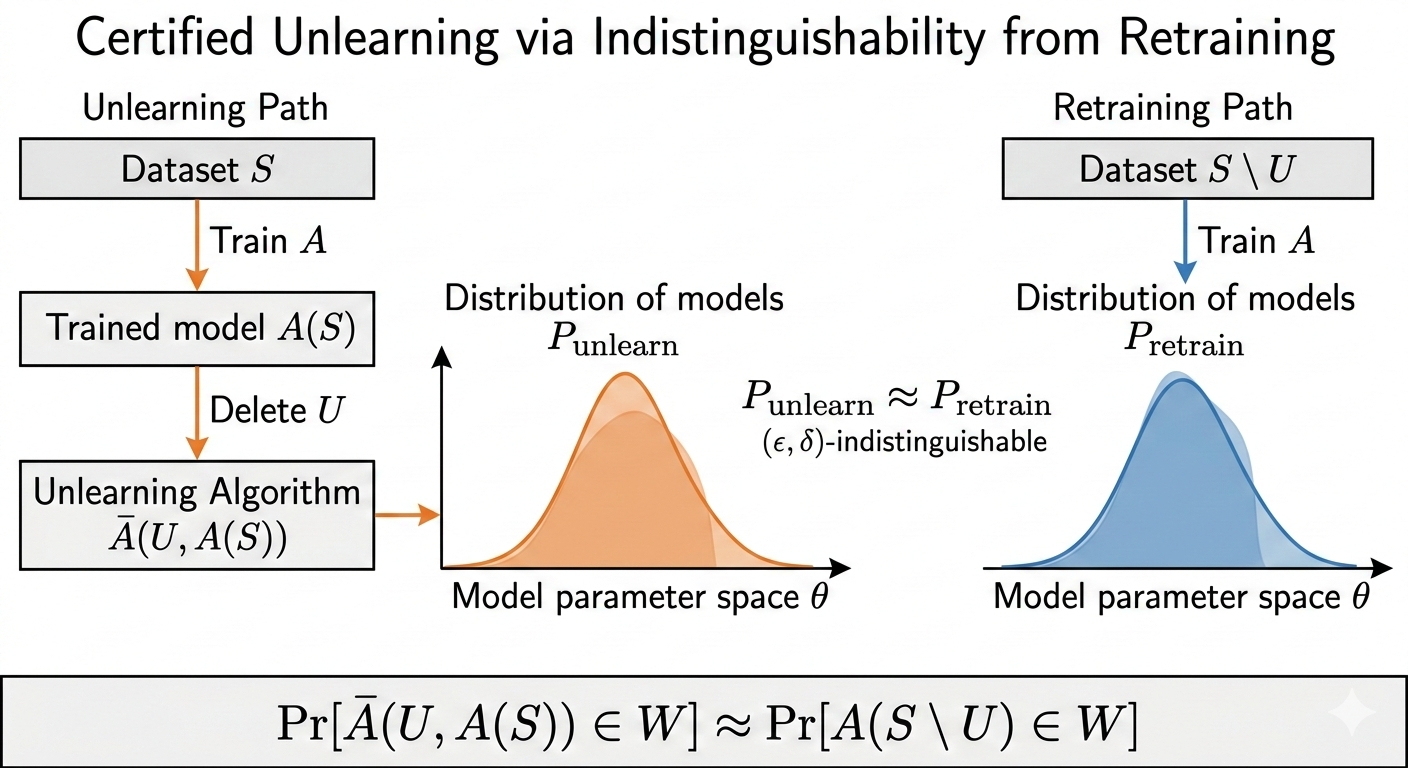
The above approach to algorithmic unlearning was initially the strongest candidate for the problem posed above with tighter bounds for deletion capacity. The method trains models while only injecting noise to the model at deletion-time. Sekhari proves regret bounds significantly tighter than DP-style unlearning by using a standard trick from online convex optimization theory: a Newton update.
The Newton update is paired with a calibrated noise mechanism that specifically reduces the model’s sensitivity to the deletion without compromising accuracy.
The Newton update addresses the shortcomings of prior methods. It allows the engineer to set a threshold for unlearning, with a lower threshold experiencing a smaller amount of deletion noise. And because the method adds noise to the update, the model’s sensitivity with respect to the deleted data is obscure. This prevents the adversarial attacks we discuss earlier.
It also raises the bar on model quality. His unlearning definition requires strong model inference not only for training data that the model has seen, but the population data it has yet to learn. In other words: models need to unlearn without losing the ability to generalize to previously unseen data.
A New Method: Online Unlearning for Stateful Optimizers.
A previous experiment showed something surprising. When we delete the data from the history of a first-order gradient descent optimizer, the model realigns to the new loss surface easily. Second-order optimizers, however, show a persistent trace of the deleted data. It actually destabilizes the model’s learning process as it tries to make sense of a world where the data it observed simply no longer exists. And though this residual instability doesn’t affect the model’s performance, it does leak information about the model itself.
This is a deeply subliminal threat: a model can leak information without indicating any external performance indicators. Engineering teams (and regulators) will need to evaluate more than the model’s immediate state for sufficient privacy.
This is backed up in the literature. Chen et al. show that adversarial deletion requests can leak key model information [Chen_Zhang_Wang_Backes_Humbert_Zhang_2021]. They argue that, when an adversary knows in advance the data to be deleted, then she may reconstruct the influence of the deleted points by comparing the model before and after deletion. Not only does this leak information about the model itself, but allows the adversary to submit deletions with the explicit goal of destabilizing the model’s performance.
It also opens the door for more efficient unlearning methods. A memory constraint that grows linearly with the sample size is unideal, as is the Hessian inversion, but methods like L-BFGS-style optimization allow for efficient sketching with bounded error terms [prudente2024]. Indeed, Qiao et al. implement a Hessian sketch unlearning method that unlearns an observation in constant time [qiao2025].
And so Sekhari’s definition opens up doors. We have a new toolbox to approach unlearning and build lean, secure models. We also have a formal definition of unlearning that raises the bar on privacy and performance.
The next feasible step is to scale it to production: build a model that learns and unlearns on the fly with minimal performance loss.
References
- Qiao, Xinbao, Zhang, Meng, Tang, Ming, Wei, Ermin (2025). Hessian-Free Online Certified Unlearning. arXiv. https://doi.org/10.48550/arXiv.2404.01712
- Yinzhi Cao, Junfeng Yang (2015). Towards Making Systems Forget with Machine Unlearning. IEEE. https://doi.org/10.1109/SP.2015.35
- Chen, Min, Zhang, Zhikun, Wang, Tianhao, Backes, Michael, Humbert, Mathias, Zhang, Yang (2021). When Machine Unlearning Jeopardizes Privacy. arXiv. https://doi.org/10.48550/arXiv.2005.02205
- Dwork, Cynthia, Roth, Aaron (2014). The Algorithmic Foundations of Differential Privacy. Foundations and Trends® in Theoretical Computer Science. https://doi.org/10.1561/0400000042
- Bourtoule, Lucas, Chandrasekaran, Varun, Choquette-Choo, Christopher A., Jia, Hengrui, Travers, Adelin, Zhang, Baiwu, Lie, David, Papernot, Nicolas (2020). Machine Unlearning. arXiv. https://doi.org/10.48550/arXiv.1912.03817
- Ginart, Antonio, Guan, Melody Y., Valiant, Gregory, Zou, James (2019). Making AI Forget You: Data Deletion in Machine Learning. arXiv. https://doi.org/10.48550/arXiv.1907.05012
- Chen, Min, Zhang, Zhikun, Wang, Tianhao, Backes, Michael, Humbert, Mathias, Zhang, Yang (2021). When Machine Unlearning Jeopardizes Privacy. arXiv. https://doi.org/10.48550/arXiv.2005.02205
- Prudente, L. F., Souza, D. R. (2024). Global convergence of a BFGS-type algorithm for nonconvex multiobjective optimization problems. arXiv. https://doi.org/10.48550/arXiv.2307.08429
- Qiao, Xinbao, Zhang, Meng, Tang, Ming, Wei, Ermin (2025). Hessian-Free Online Certified Unlearning. arXiv. https://doi.org/10.48550/arXiv.2404.01712